
I have been working with React for about four years now. It has been quite a ride and for the whole time the data dependencies management has been an important topic for me. In this article, I would like to show you my journey with the data dependencies management and the result I came up with.
Disclaimer: This first article is focused on setting a background for what I'm going to explain in the next article. If you are expecting some solution for the problem, wait for the next article. :)

At the beginning of my journey with React I used it the same way as I was using the rest of JavaScript world (meaning jQuery). JavaScript was just a nice extension to already working user interface. The whole website was created at the server side and just a small part of the website was dynamic at the user side. The data for the JavaScript part were injected to the rendered HTML at the server side and consumed by JavaScript at the user side. I used this approach for my small parts of frontend written in React. And it worked well! The dependencies for a given page were there when needed, injected by the server and consumed by React.
Single Page Applications
Then I started to work in Ackee and somehow all the applications I have worked on happened to be SPAs. I don't want to dive deep in SPAs and what they are and when and why to use them, but for those who doesn't know what SPA means; Single Page Application is an application written in JavaScript, running in a browser and dynamically manipulating an HTML file instead of requesting a new HTML file from a server.
One of the big problems accompanying SPAs (and there are plenty of them) was the data dependencies management. Injecting data for JavaScript into HTML at the server side was obsolete. It doesn't make sense to inject all the data for the whole application at the server render time. So, what should one do?
Luckily for me, a lot of new cool libraries showed up at the time. React Router for rendering the SPA's content based on url was the starting point. In combination with basic AJAX calls, we were able to fetch the data for the current content rendered by React (each component is requesting the data it needs). So we were able to request the data on demand when they were needed, but where and how to store them? In a component which requested for them? Or in a global variable? Some storage? Where?
Flux
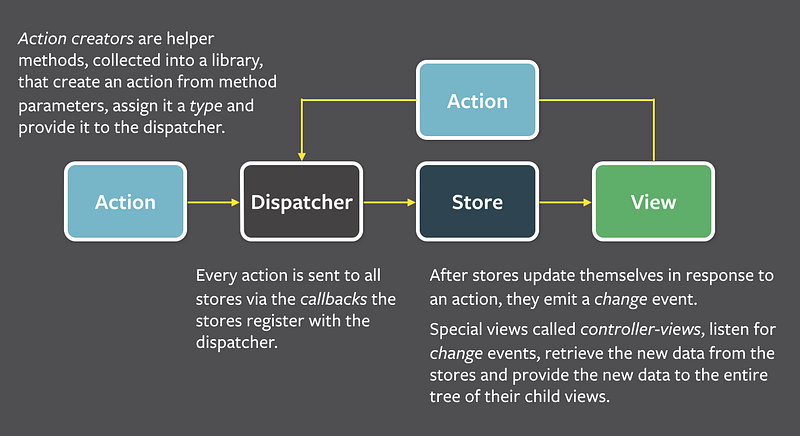
Again, luckily for me, Facebook invented a new cool application architecture called Flux at the time. Flux is not only about storing application data but it is also about the whole data flow. The data flow in Flux is unidirectional and the data can be modified only using so-called actions (no public setters or getters). An action defines a data manipulation. Each action is queued and then applied on a store. There can be more stores in your application, each holding a part of the data dependencies. After the content of a store is changed, the store emits a “change” event for registered UIs. The UI can then update itself based on the new data. You can see the flow on the diagram below. The data is stored in some global stores and updated only via dispatched actions. UI can observe the stores to render/re-render itself if the data it depends on has changed. Cool, isn't it? Do we need something else?
Redux
There was a really big boom after Flux showed up. A lot of libraries tried to implement Flux and we were forced (“forced”) to choose one. So we picked Marty.js. A great one, I have to admit, but after a while we realized it has some cons. The first of the cons: Flux emphasizes usage of more than one store. This sucks! It can add so much boilerplate code into your application. The next one: to be honest, Marty tries to be more of a framework than a library and forces you to use its infrastructure for fetching data dependencies and other things and we were forced to hack it a few times. And then Redux showed up (God bless Dan Abramov). What is Redux?
I'm going to cite this cool article: Redux = Flux + Functional programming. Flux itself is just a proposal of an architecture. Redux is a library, an implementation of Flux. But Redux breaks one rule: it has only one store! So, once again, Redux is an implementation of Flux using just one store. Where is the functional programming? As I've said before, Flux itself doesn't say anything about an implementation. So how to apply actions on the store? Use the functional programming!
const initialState = { counter: 0 };
const previousState = ...;const reducer = (state = initialState, action) => {
switch(action.type) {
case 'INC':
return {
...state,
counter: state.counter + 1;
};
default:
return state;
}
}const newState = [action1, action2, action3].reduce(reducer, previousState);As you can see above, we have a previousState, a reducer function, a queue of actions and using the reduce method we can generate a new state of our application. That's all! Redux is pretty lightweight. It gives you a store wrapper so you can dispatch actions on the store, and it gives you an ability to observe the store for changes. You give it a reducer function and initialState. The rest of the work is on you. No boilerplate code, no forced (kind of) infrastructure….. wait! Where to do some API calls?
Redux-saga and excluding the business logic
Marty.js did a clever thing. It extracted the business logic outside of React components into its infrastructure. Separation of concerns in practice, cool! But by adopting Redux, we returned back to fetching data in React components, which means mixing up business logic with the data rendering. Redux itself is just too simple. Not cool, not cool.
Luckily for us, Redux has a solution for this problem. Redux allows developers to extend it via middlewares. A middleware is a store extension allowing us to manipulate actions dispatched on a store before they finally reach the store. Thanks to middlewares, we can dispatch arrays of actions, functions and so on and so on.
We started with redux-thunk middleware. It allows us to dispatch a function as an action. The signature of the functional action is (dispatch: Function, getState: Function) => null . As we can see, redux-thunk gives us a full access to the store and allows us to write business logic in actions. Better than nothing, but not that cool at all.
Then we've discovered redux-saga and it completely changed the way we're writing Redux applications now. Redux-saga is a middleware but you can think about it as a business logic of a Redux application. It uses async generators to create business logic layer. When creating the middleware, you give it a root generator to be ran and the middleware calls it. In the root generator, you can call other generators, wait for actions, create new actions, select data from the store, perform API calls etc. (it is crazily powerful, check out the documentation). For example, it allows you to handle complex logic like refreshing access tokens when API returns 401. Thanks to Redux-saga you can dispatch only plain actions in your React components and then handle the rest in the middleware.
The conclusion
I have led you more than half through my experience with React and its ecosystem. What to take from here? React is a library for UIs. Don't use it to store the data, don't even use it to fetch the data. Use it just to ask for the data. Flux allows you to avoid side effects in your application thanks to its unidirectional data flow. The data are stored in stores and manipulated just by actions. Redux uses just one store, the single source of truth, to store the data. It uses functional programming (reducer functions) to manipulate the data. It simplifies Flux, it makes applications more predictable, it is easy to test, and it even allows you to easily create time traveling! And Redux-saga gives you an incredibly powerful layer for you business logic and the data dependencies management!
Do you want to know how we use Redux-saga to handle our data dependencies? I'm going to explain it in the upcoming article. Stay tuned!





