A few weeks ago, Google announced its own AI model called Gemini, which has emerged as a significant competitor to ChatGPT. Along with the chatbot launch, Google also released an SDK for developers. This article will delve into the Android SDK and explore its capabilities.
Gemini
Gemini is a series of multimodal generative AI models from Google. Let’s describe what it means in simple terms.
A generative AI model can generate text by guessing which character will likely be next in a sequence of already generated characters. For us viewers, we are communicating with a seemingly intelligent machine that responds with meaningful ideas. The idea behind this is fairly simple. The model learns from a large amount of data, called the knowledge base, and seeks patterns and relations among the data. Using statistics, it predicts the upcoming character, yet the model doesn’t understand the meaning.
As mentioned, Gemini is a series of multimodal models. This means it can process information in various formats, such as text, image, voice, and others, as we will show later.
Speaking about the series, Gemini covers multiple models, which might be slightly confusing.
Gemini Models
Google initially announced three AI models—Gemini Nano, Gemini Pro, and Gemini Ultra—in December 2023. Why do we have three of them? They differ in efficiency and capability. Gemini Nano is the most efficient model and runs on the silicon of some of the newest Android devices. It works offline, and developers may use it to enhance their app experience.
Gemini Pro provides a good compromise between power and speed. The Gemini chatbot uses this model for the public, and the Gemini SDK also empowers it. Gemini API offers different models optimized for specific use cases, such as Gemini 1.5 Pro, Gemini 1.5 Flash, Gemini 1.0 Pro, and Gemini 1.0 Pro Vision. Higher versions are more capable. Almost all of these models can process text and images as input but can only respond in text for now when writing the article.
Gemini Ultra is the largest and most capable model for highly complex tasks. With a score of 90.0%, it is the first model to outperform human experts on MMLU (massive multitask language understanding), which uses a combination of 57 subjects, such as math, physics, history, law, and others. It will be a paid experience, though. Whether developers can access the API is uncertain at this time.
Let's build the app
Google has decided to release an SDK to make working with the Gemini API easier. In this article, we will explore the SDK for Android. However, the concepts should also apply to languages such as Swift, Node.js, or Python.
Firstly, we need to start by getting the API key from Google AI Studio and declaring the correct dependency in the module's build—gradle file.
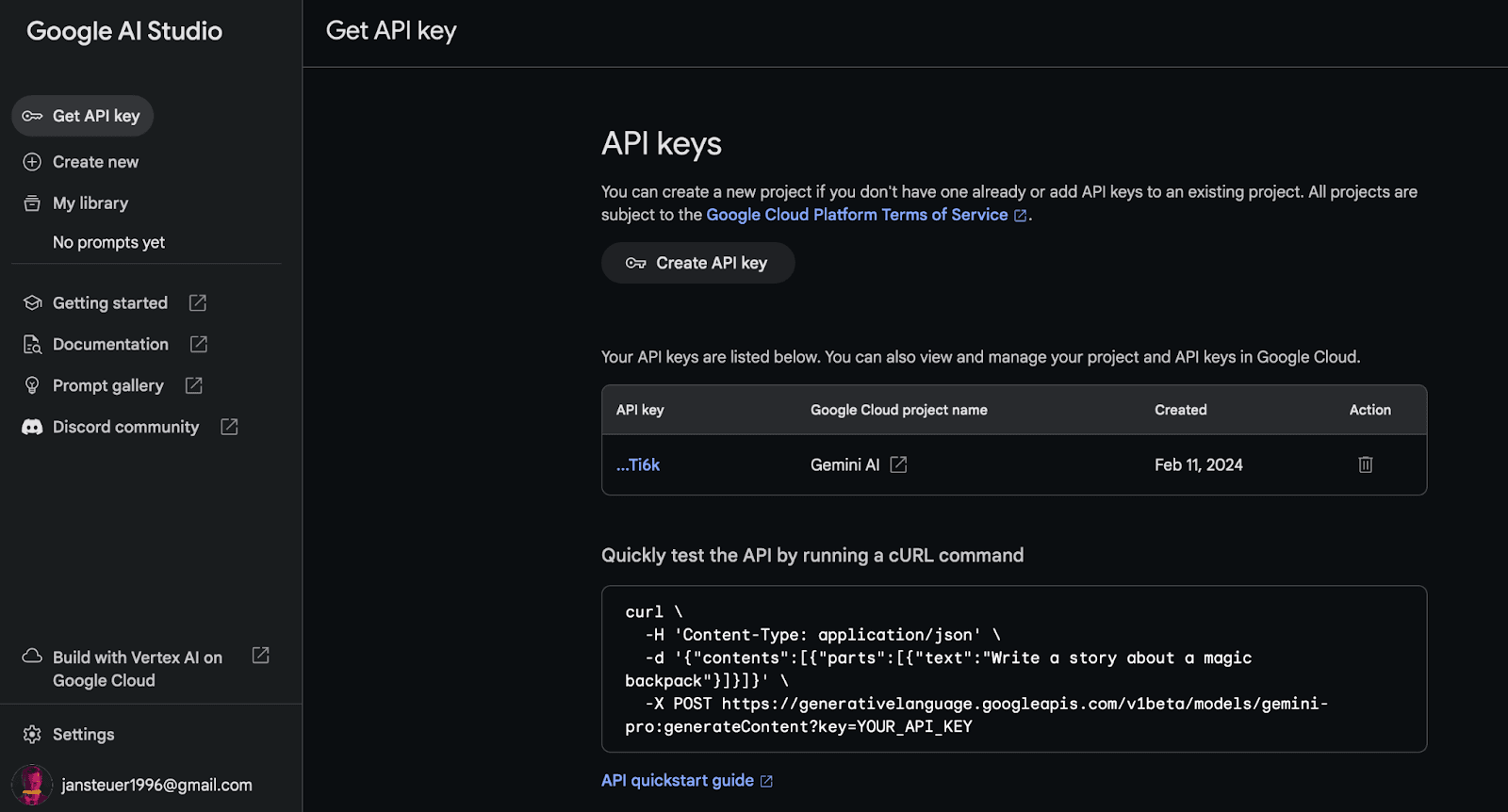
implementation("com.google.ai.client.generativeai:generativeai:0.2.0")Then, we can access the GenerativeModel class, which serves as the main entry point for all operations with the model. It has four parameters: modelName, apiKey, generationConfig, and safetySettings.
val model = GenerativeModel(
model = "gemini-1.5-flash-001",
apiKey = BuildConfig.apikey,
generationConfig = generationConfig {
temperature = 0.15f
topK = 32
topP = 1f
maxOutputTokens = 4096
},
safetySettings = listOf(
SafetySetting(HarmCategory.HARASSMENT, BlockThreshold.MEDIUM_AND_ABOVE),
SafetySetting(HarmCategory.HATE_SPEECH, BlockThreshold.MEDIUM_AND_ABOVE),
SafetySetting(HarmCategory.SEXUALLY_EXPLICIT, BlockThreshold.MEDIUM_AND_ABOVE),
SafetySetting(HarmCategory.DANGEROUS_CONTENT, BlockThreshold.MEDIUM_AND_ABOVE),
)
)We will work the most with the model name parameter. This parameter represents the name of the model we want to use depending on our use case. Some examples are: “Gemini-1.5-pro”, and “Gemini-provision”. Each model is optimized for slightly different tasks. You can read more here.
The apiKey parameter is used for billing purposes. The models are free of charge if we pass rate limits. However, this might change in the future, so you better always check the pricing site.
We didn’t cover the last two more advanced parameters. We will explain them later in this article to finally show some examples.
Text-to-text use case
The most straightforward example is the text-to-text use case. We call the generateContent() method with our text prompt. It is a suspended method (needs to be called from a coroutine) that returns a GeneratedContentResponse.
Text-to-text with streaming use case
The Gemini API offers an alternative method for receiving responses from generative AI models – through a data stream. With a streamed response, the model sends incremental data back to our application as it is generated, allowing us to quickly respond to user requests, show progress, and create a more interactive experience. We only have to call the generateContentStream() method that returns the Kotlin Flow of GeneratedContentResponse with a new-coming response.
scope.launch {
var outputContent = ""
model.generateContentStream(inputContent)
.collect { response ->
outputContent += response.text
}
}Can we add images?
It’s been boring so far without any images. Luckily, we can send a text prompt with an image to a Gemini 1.5 model specialized for vision-related tasks, such as image captioning or object identification. We have to provide a content() method that is a builder. In the content block lambda function, we might add text using the text() method or images with the bitmap() method. We can even provide multiple texts or images at once by chaining the methods one after another. It’s important to say the order matters. If we give the model with a single image, place the text prompt after the image for better results.
val inputContent = content {
image(bitmap)
text("What is the object in this picture?")
}When we have the instance of content, we pass it to either the generateContent() or generateContentStream() method.
scope.launch {
val response = model.generateContent(inputContent)
}We can provide only some image types:
- PNG - image/png
- JPEG - image/jpeg
- WEBP - image/webp
- HEIC - image/heic
- HEIF - image/heif
If you ask whether we can upload a PDF, the answer is no. Not at this time. However, we can convert the PDF to a bitmap and work with it like an image.
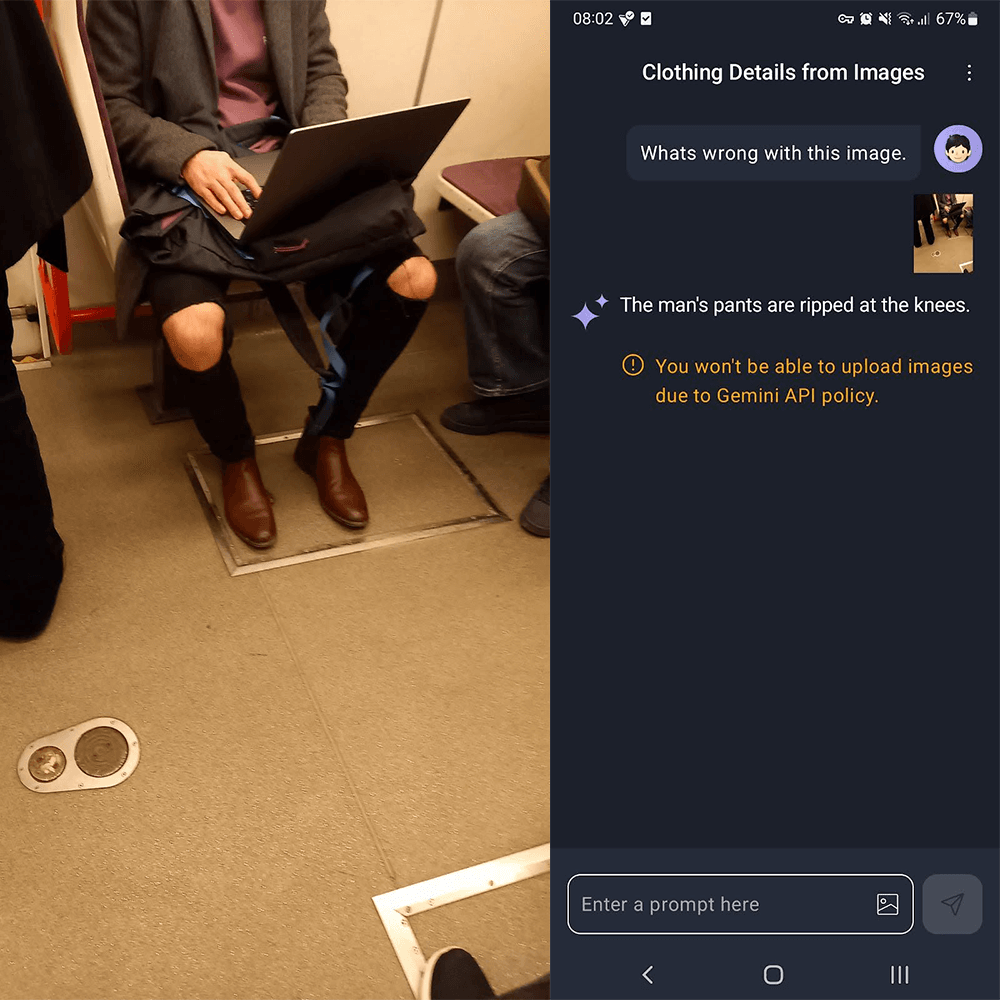
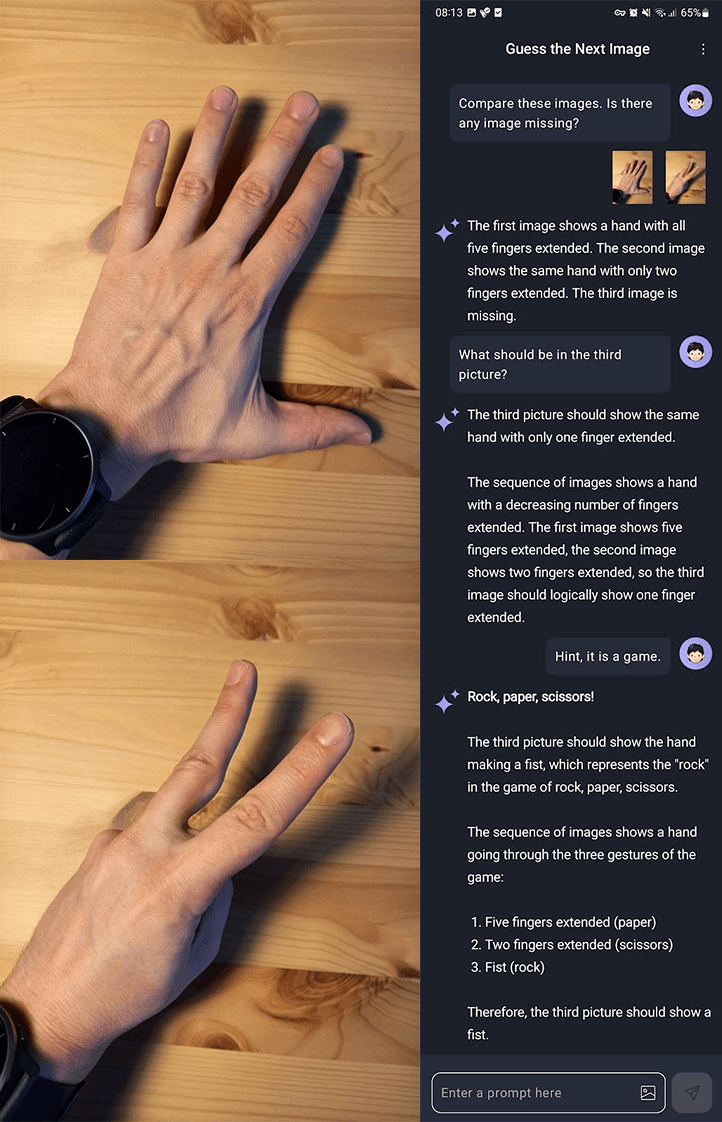
What about some chatting?
Using Gemini, we can build freeform conversations across multiple turns. To create a new chat, we can use the Gemini 1.5 model or the Gemini 1.0 Pro model. We start the chat by calling the startChat() method and then use the sendMessage() method to send a new user message.
Internally, Gemini SDK remembers the history of messages for us. If we need to provide a context for the model, we can pass a list of Contents (by content() lambda) to the startChat() method. We assign each content a role, either user (the role that provides the prompts) or model (the role that responds). They must alternate.
val chat = model.startChat(
history = listOf(
content(role = "user") { text("Hello, I have 2 dogs in my house.") },
content(role = "model") { text("Great to meet you. What would you like to know?") }
)
)
scope.launch {
val response = chat.sendMessage("How many paws are in my house?")
}However, this approach has its limits. We can only use Gemini Pro models. That means we cannot send images in a chat. The second limitation is that we cannot configure the model (instance of the GenerativeModel) at runtime.
To mitigate this, we can take on the responsibility of managing the chat history and passing it to the method generateContentStream(). This allows us to configure the model by adjusting safety settings, while also maintaining our chat history. When the model rejects a query due to a safety breach, it's crucial for the user to tweak the settings to allow the model to respond. As previously mentioned, it's crucial to alternate the roles to prevent runtime exceptions.
private val chatHistory: MutableList<Content> = mutableListOf()
aiModel.generateContentStream(*chatHistory.toTypedArray())Advanced model parameters
Speaking about safety settings, we have yet to explain what they are. With safety settings, we tell the model how much it should filter responses regarding security. We pass the settings as one of the parameters in the GenerativeModel class constructor. Google provides us with four types of thresholds:
- BLOCK_LOW_AND_ABOVE blocks when there is a low, medium or high probability of unsafe content.
- BLOCK_MEDIUM_AND_ABOVE blocks when there is a medium or high probability of unsafe content.
- BLOCK_ONLY_HIGH blocks when there is a high probability of unsafe content.
- BLOCK_NONE shows content regardless of the probability of being unsafe.
We can use these flags for any of the four filter categories, specifically harassment, hate speech, sexually explicit content, and dangerous content.
The last advanced GenerativeModel parameter we didn't cover is a generation config. The generationConfig parameter specifies how the content is generated. The most common are max output tokens, temperature, topK, topP, and stop sequence parameters.
The max output tokens parameter specifies the maximum number of tokens that can be generated in the response. A token is approximately four characters, so 100 tokens roughly correspond to 60-80 words.
Temperature controls the degree of randomness in token selection. The lower the temperature, the more deterministic (predictable) the answer. If we set the temperature to 0, the most probable response is always picked. With higher temperatures, we might get more creative and less consistent answers.
TopK and TopP parameters are related to token selection. The topK defines how many of the most probable tokens use temperature, and the model selects the next one for the response. The topP value specifies which tokens sorted from the most to least probable are picked until the sum of their probabilities (that they will be picked up) equals the topP value.
How to design our prompts?
Designing our prompts well is half of the success. If we want to be successful with our question, we must pick a correct prompting strategy. We can choose from zero-shot, one-shot or few-shot strategies.
The simplest one is a zero-shot strategy. It involves asking the model without any examples that it can replicate. The model relies only on its knowledge.
The following strategy is a one-shot. We provide a single example. Therefore, we might get more predictable responses. Take a look at the prompt:
Food: apple Pairs with: red Food: pear Pairs with:
In this example, the model responds with green.
The last and most advanced strategy is a few-shot strategy. As the name suggests, we supply the model with multiple examples. This strategy is suitable for more complicated tasks such as:
Generate a grocery shopping list for a week for one person. Use the JSON format given below. Use a metrical system. {"item": "eggs", "quantity": "6"} {"item": "bread", "quantity": "one loaf"}
We get this answer:
[ {"item": "eggs", "quantity": "6"}, {"item": "bread", "quantity": "one loaf"}, {"item": "milk", "quantity": "1 liter"}, {"item": "chicken", "quantity": "500 grams"}, {"item": "rice", "quantity": "1 kilogram"}, {"item": "broccoli", "quantity": "1 head"}, {"item": "apples", "quantity": "5"}, {"item": "yogurt", "quantity": "500 grams"}, {"item": "cheese", "quantity": "200 grams"}, ]
Conclusion
The Gemini SDK from Google provides developers with robust tools for integrating advanced AI capabilities into their applications. With models ranging from the efficient Gemini Nano to the highly capable Gemini Ultra, there are options to suit various needs and performance requirements. The SDK's support for multimodal inputs, such as text and images, along with its configurable safety settings and content generation parameters, offers a flexible framework for development.
This article showcases practical examples of the Gemini SDK's capabilities, including text-to-text generation, streaming responses, image processing, and chat functionalities. These examples vividly illustrate the SDK's versatility and ease of use. However, certain limitations, such as the inability to use images in chat and the need to manage some configurations manually, highlight areas where the SDK could improve.
As AI continues to evolve, the Gemini SDK represents a significant step forward, though not without its challenges. The Gemini models provide a strong foundation, but these tools' ongoing development and refinement will be crucial for fully realizing their potential in various applications.